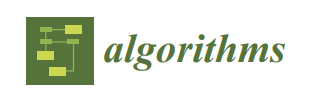The Central Kurdish Speech Corpus Construction serves as a crucial data source for developing text-to-speech systems. Despite its significance, two primary challenges hinder its optimal performance: inefficiencies in training and analysis, as well as difficulties in modeling. The most significant barrier to text-to-speech in the Kurdish language is the lack of efficient tools and pure and clear datasets. To tackle this issue, the corpus introduces the Gigant KTTS, a large Kurdish Text-to-Speech Dataset, which includes written sentences and speech corpus for the Central Kurdish dialect. To ensure diversity, a variety of subjects recorded the 6,078 sentences covering 12 document topics in a professional studio. These sentences were recorded by a Kurdish male dubber to accurately represent the Central Kurdish dialect. The recording process utilized a combination of audio and visual sources in a controlled, low-noise environment, resulting in a total recording duration of 13.63 hours, with the sentences saved in the WAV format. The process of recording and editing audio took 10 days to complete. It included capturing 6078 WAV files and 13.63 hours of recorded speech. The audio files are saved in WAV format, and the text sentences are stored in an Excel file. All audio files are stored in a single folder, and their names include the file extensions. Each transcript corresponds to a specific audio file and is referenced by an ID, which is the same as the audio file's name. The dataset was prepared to conform to a Gaussian distribution, enhancing the effectiveness of model training and minimizing bias in record length.